Document Filters 25.2 Release

Document Filters 25.2 advances our shift-left strategy by enhancing traceability, data integrity, and extensibility within content pipelines. With this release, Document Filters becomes the first solution to embed positional metadata directly into Markdown for all our supported formats, setting a new benchmark for transparency and explainability in AI and search-driven workflows. We’ve also improved Markdown’s handling of complex tables, enabling seamless extraction of structured data from even the most irregular layouts. In addition, table extraction is now supported for XFA PDFs, a long-standing challenge for automation and compliance initiatives. Finally, a new custom OCR callback interface gives teams the freedom to integrate any OCR engine into their workflow, unlocking multilingual, domain-specific, and image-heavy content for broader automation. Each of these updates contributes to cleaner, more connected data earlier in the process—reducing errors, manual fixes, and integration complexity. Let’s take a closer look at what’s new.
Watch as we walk through a few of the new features in the 25.2 release of Document Filters.
Positional Metadata in Markdown and JSON
Document Filters now supports embedding positional metadata in both Markdown and JSON outputs, allowing each extracted element to be traced back to its original location in the source file. This includes paragraphs, tables, lists, and bounding boxes that are critical details for high-trust workflows like intelligent search, summarization, and document auditing. For AI systems, this positional context improves explainability, allowing answers or insights to be visually or programmatically tied back to the source, boosting confidence in model outputs.
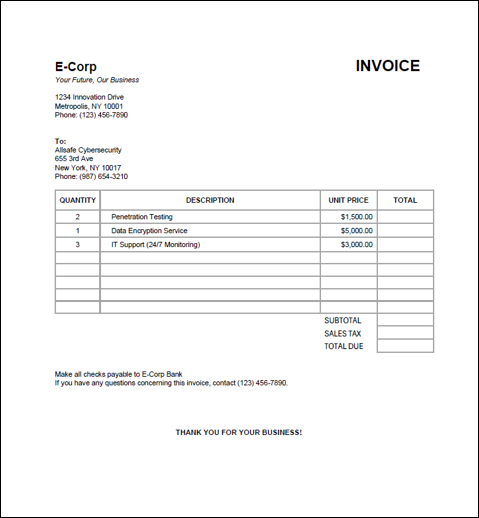
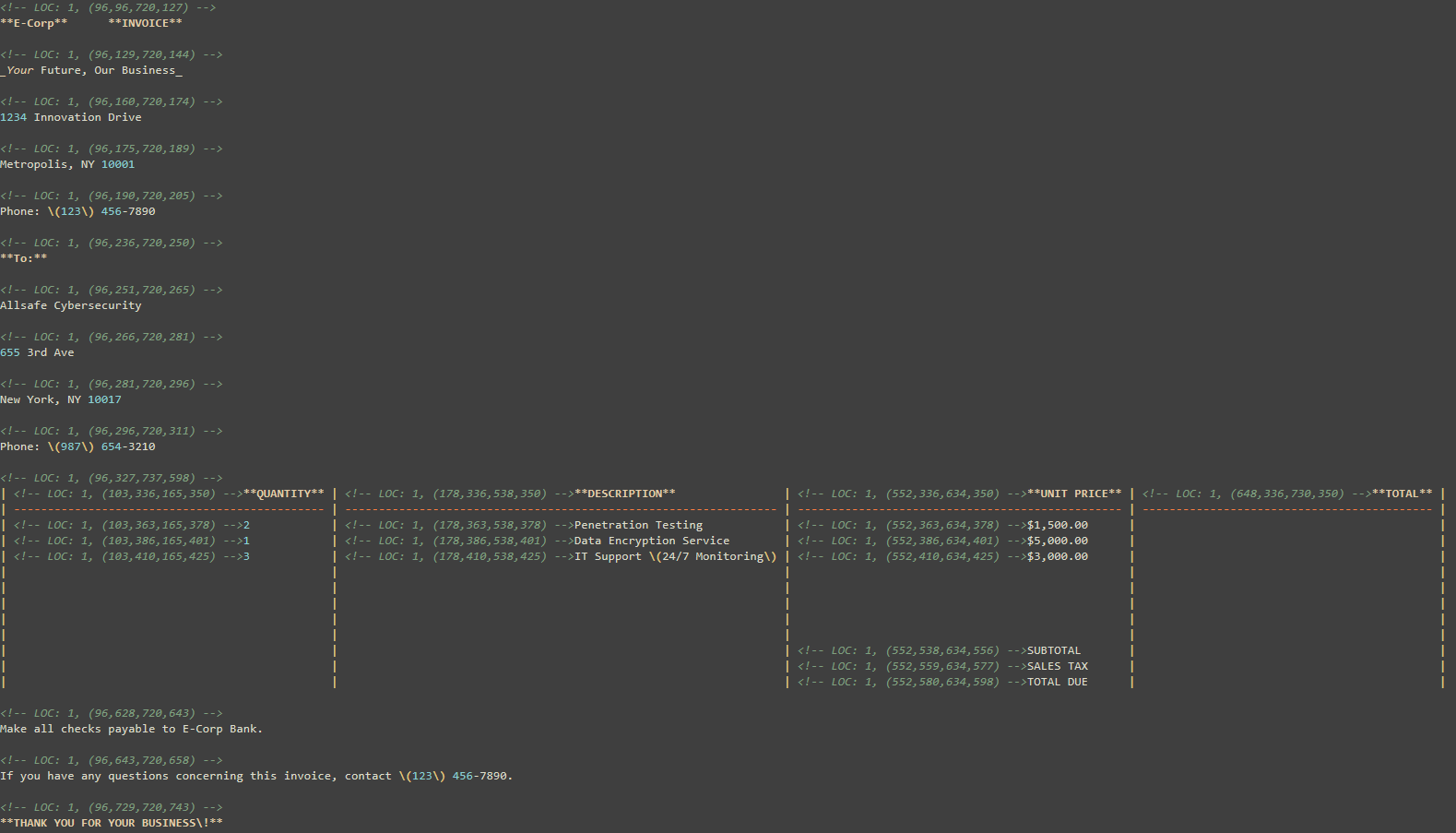
To enable this, set the MARKDOWN_INCLUDE_LOCATIONS or JSON_INCLUDE_BOUNDS option in your configuration.
Complex Table Support in Markdown
Tables with embedded lists, multi-line content, or irregular layouts (complex tables) are now preserved more faithfully in Markdown using sanitized inline HTML. This improves support for documents like financial reports, regulatory filings, and academic papers where real-world tables often defy simple formatting.
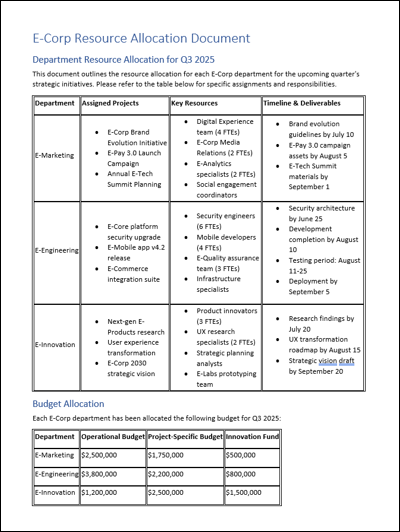
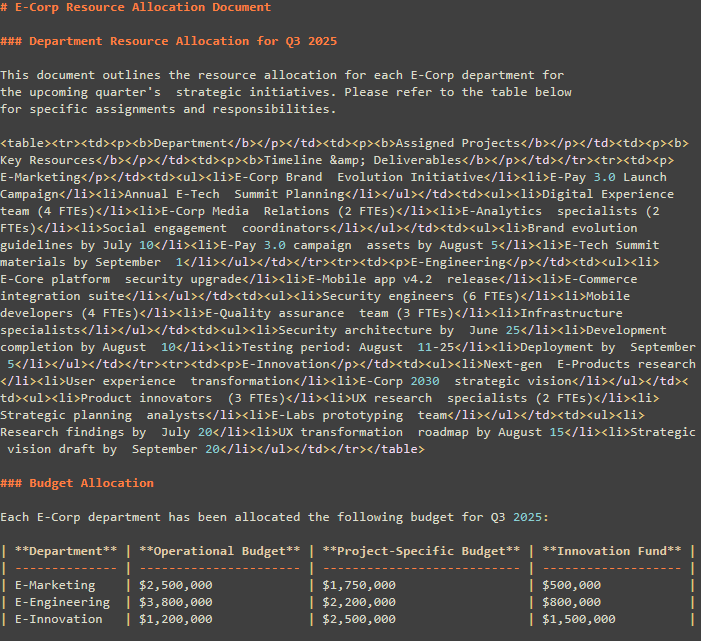
Previously, these tables could be flattened or misinterpreted, requiring downstream rework. Now, data integrity is maintained across all formats, making Markdown more reliable for analytics pipelines and downstream AI processing, especially for models that ingest tabular data for classification or trend analysis.
Table Extraction from XFA PDFs
XFA-based PDF files, which are common in enterprise forms and legacy systems, can now be parsed for tabular data using Document Filters. This opens new possibilities for automating extraction from static or interactive PDFs that were previously difficult to analyze.
For industries like government, insurance, and healthcare, where XFA PDFs are still in use, this enhancement accelerates automation without requiring expensive format conversions or manual intervention.
Custom OCR Integration with Callback Support
A new OCR callback interface lets teams plug in any OCR engine, including open-source tools like EasyOCR or services like AWS Textract, directly into the Document Filters workflow. This supports multilingual, domain-specific, or high-accuracy OCR strategies, while maintaining a consistent output structure.
The callback is lightweight and language-agnostic, making it ideal for AI pipelines that require customized text recognition from images, scanned forms, or handwritten documents. Whether you’re building classification models, search tools, or extraction engines, this update gives you full control over how OCR fits into your document processing flow.
Release Links
- Document Filters 25.2 Release Notes
- Document Filters 25.2 Software Bill of Materials
- Enhancement Requests