Document Filters 24.4 Release

The latest release of Hyland Document Filters introduces features that streamline document processing and enhance efficiency, supporting the broader 'shift-left' strategy. By empowering users to control data earlier in the workflow, these updates reduce complexity and improve performance across AI/ML applications. New content cleaning options simplify data preparation, making it easier to generate machine-friendly content, while the Simplified JSON output format accelerates data extraction and processing. Additionally, the new text-mode Markdown support lowers resource consumption, allowing for more efficient handling of large documents. With the addition of a Python package, users can also integrate Document Filters seamlessly into development workflows, enhancing overall productivity and workflow efficiency.
Watch as we walk through a few of the new features in the 24.4 release of Document Filters.
Simplified JSON Output Type
The new Simplified JSON output type provides a lightweight, flattened representation of document structures, reducing the complexity of handling detailed document hierarchies. Ideal for AI/ML applications, it delivers structured data such as headings, tables, and lists in a simplified schema. By minimizing complexity, this feature speeds up data processing and integration, making it easier to extract information for analysis or model training. The simplified structure enhances both performance and usability, meeting the needs of modern document processing workflows.
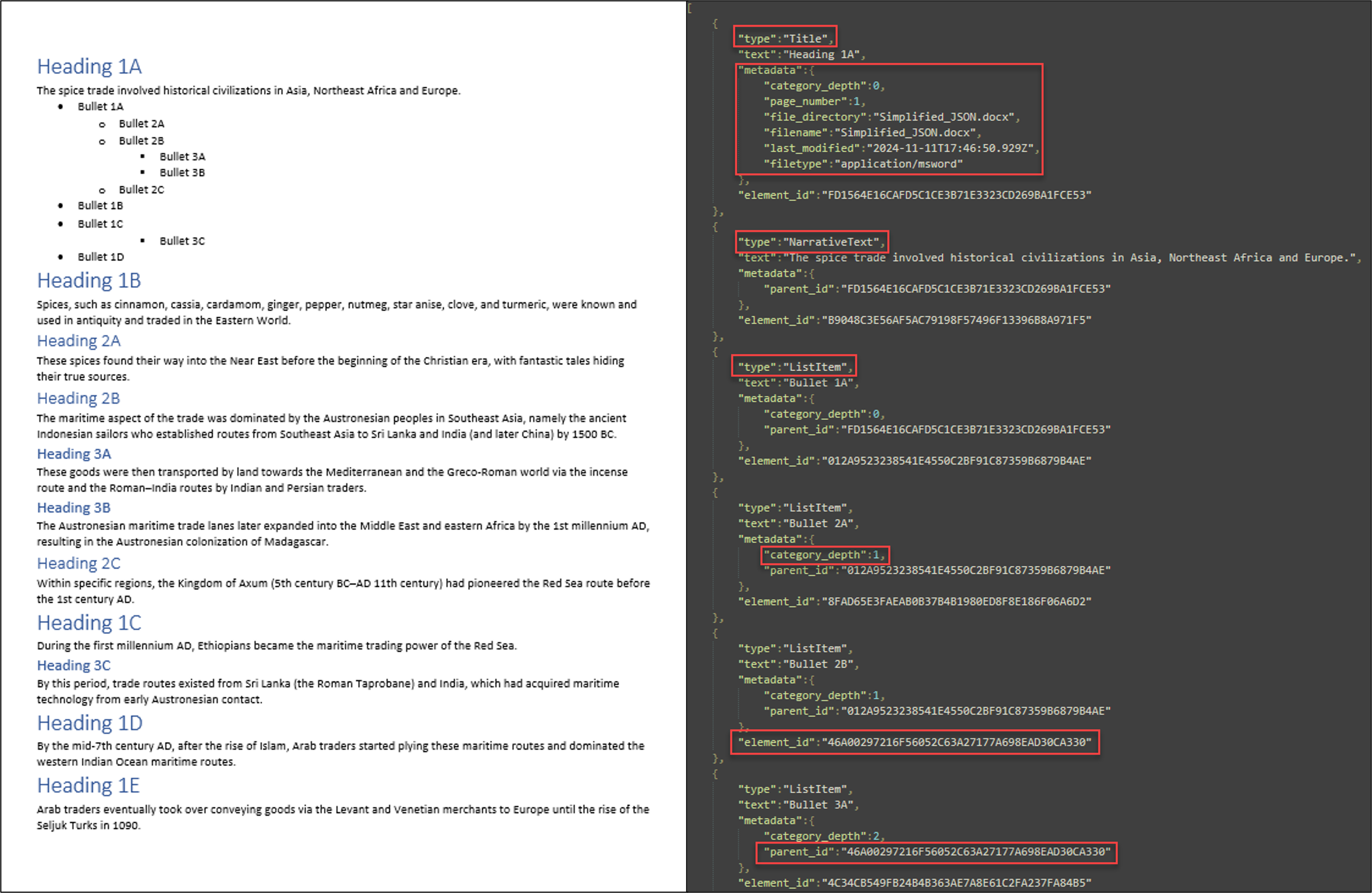
Converting a Word document into simplified JSON. The image on the left displays the original Word document with various headings, lists, and sub categories. The right image displays the same document, in a simplified JSON format, while highlighting areas of interest.
Content Cleaning
Document Filters users can now take advantage of multiple content cleaning options in both Markdown (MARKDOWN_CLEAN_CONTENT) and JSON (JSON_CLEAN_CONTENT) outputs. These functions include removing non-ASCII characters and normalizing quotes. The ability to fine-tune the cleaning process allows for greater control over the data preparation stage, reducing post-processing efforts, and making the outputs more machine-friendly for downstream AI/ML workflows.

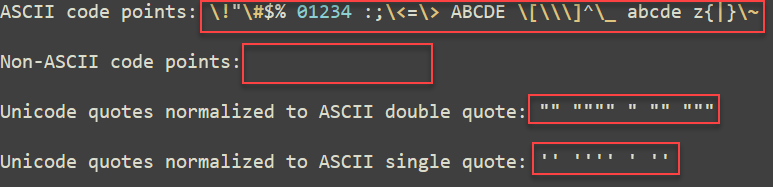
Converting a document to Markdown, while processing it with the JSON_INCLUDE_ELEMENT_ID=ON and JSON_INCLUDE_METADATA=OFF options.
Text-Mode Markdown
Document Filters now supports converting documents to Markdown format directly in text mode, eliminating the requirement for HD Mode. This enhancement offers increased flexibility, allowing users to generate Markdown output quicker and with less resource consumption. By optimizing the conversion process, this feature ensures faster, more efficient handling of large or complex documents, making it ideal for workflows that demand high performance, especially in AI/ML environments where speed and lightweight output are critical.
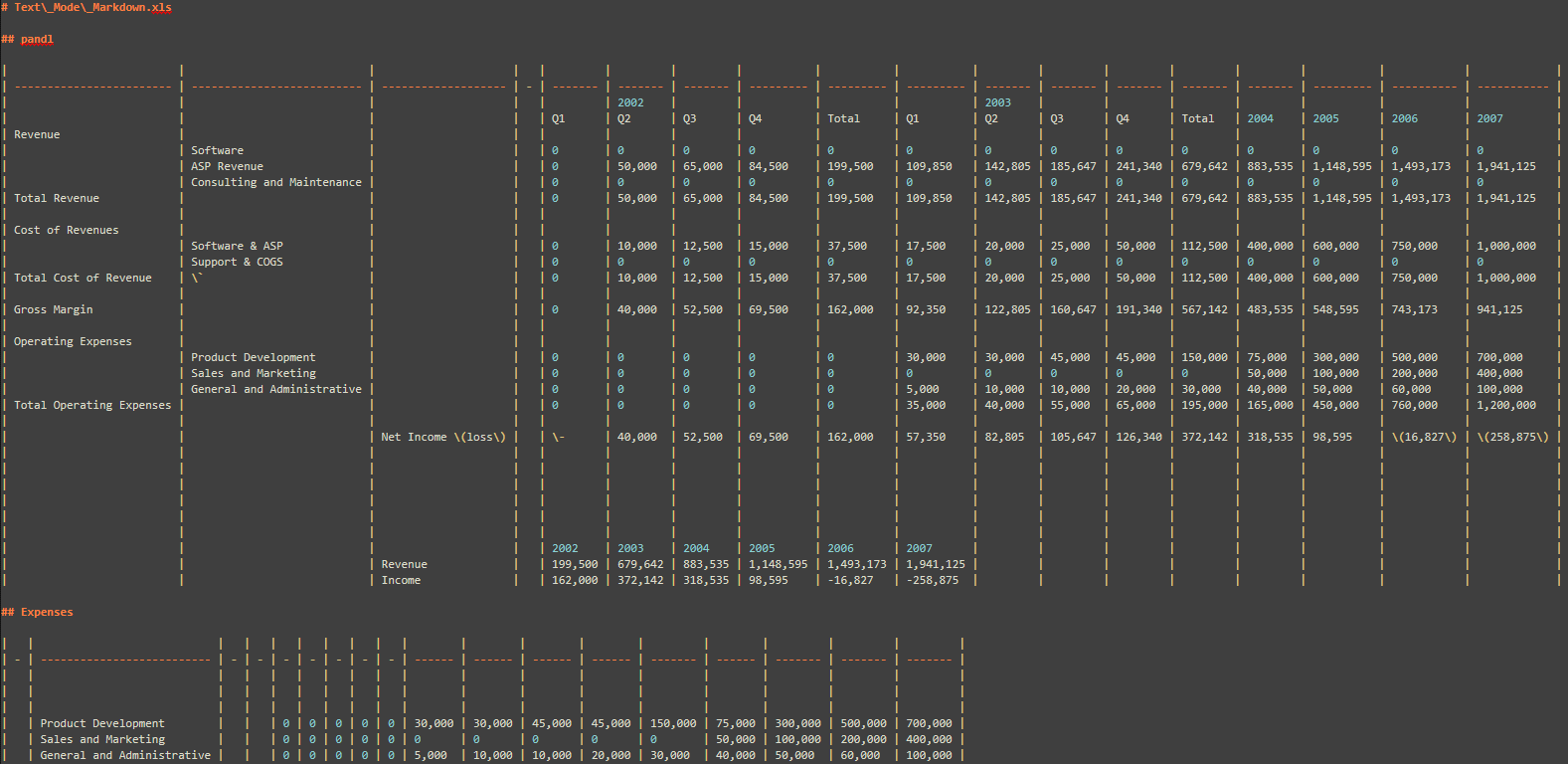
Converting a spreadsheet into Markdown while using Text-Mode, and keeping its structure.


Comparing the time it takes to convert a spreadsheet into Markdown in HD Mode and Text-Mode.
Python Package
The Document Filters Python library is now available as a GitHub package. Developers can install and update the library through standard Python package managers, allowing for seamless incorporation of Document Filters functionality into existing AI/ML pipelines, automation scripts, or content extraction tools. This update simplifies the setup and maintenance process, enabling faster prototyping and deployment of document processing solutions.
Release Links
- Document Filters 24.4 Release Notes
- Document Filters 24.4 Software Bill of Materials
- Enhancement Requests