Document Filters 25.1 Release

Document Filters 25.1 continues our 'shift-left' strategy by enhancing structured data extraction earlier in the pipeline, reducing the need for downstream corrections and transformations. This release introduces expanded structured output with improved heading detection and list recognition across multiple formats, ensuring cleaner, more reliable data for AI/ML workflows and business applications. PDF processing is also more precise, with better list mapping and automatic text unwrapping for a more natural reading experience. Additionally, file type identification now works even when only part of a file is available, minimizing unnecessary data transfers and improving processing efficiency. By delivering cleaner, more structured data from the start, Document Filters 25.1 helps streamline integration, reduce complexity, and optimize large-scale document workflows. Let’s take a closer look at what’s new.
Watch as we walk through a few of the new features in the 25.1 release of Document Filters.
File Type Identification for Incomplete Files (Community-Inspired)
Document Filters now supports identifying incomplete files using only the first 2KB of data, allowing for early detection of file types before the entire document is transmitted or processed. This capability helps optimize workflows by preventing unnecessary handling of unsupported formats or routing files more efficiently based on type. By improving file identification at an earlier stage, this enhancement enables smarter decision-making in document ingestion and processing pipelines.
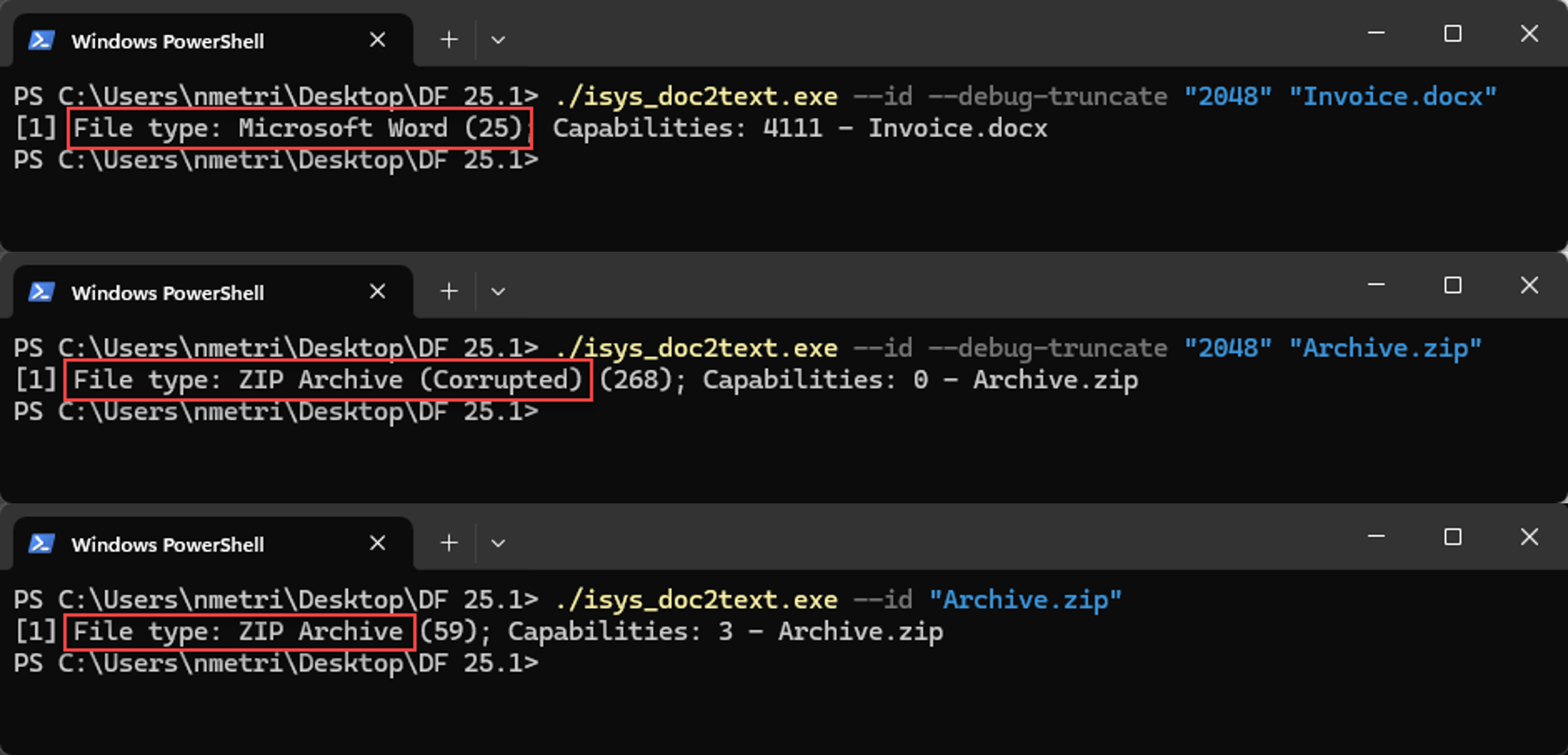
Truncating a DOCX and ZIP file to 2KB to show the behavior. The DOCX is identified correctly as a Microsoft Word file, while the ZIP file indicates that it needs more data from the file to identify correctly, as noted by the ZIP_ARCHIVE_CORRUPT file type.
Expanded Structured Output
Document Filters now delivers even more precise structured output with improved handling of headings and lists across a wider range of document formats. By refining how key structural elements are identified, this update enhances content organization and consistency, making it easier to extract and process meaningful information. These improvements reduce the effort required to normalize document structure, enabling smoother integration into AI/ML pipelines and business applications that rely on structured data.
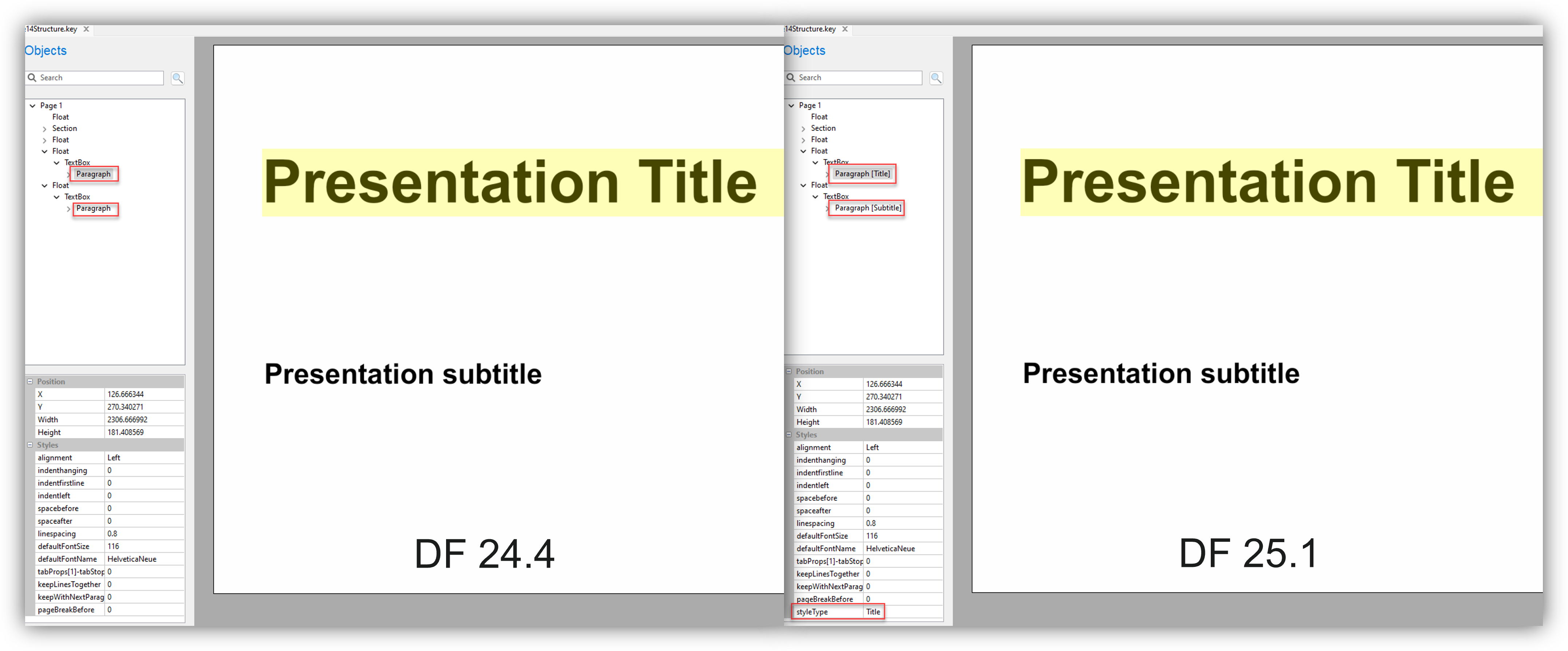
A comparison of previous and current behavior of structure detection for an Apple Keynote file. The new release is able to mark the 'title' and 'subtitle' of the slide as such.
Improved PDF Processing
Enhancements to PDF extraction now provide cleaner, more structured output when converting to formats like JSON and Markdown. Bullet and numbered lists are more accurately detected, ensuring they retain their intended formatting. Additionally, automatic handling of line wrapping eliminates unnecessary breaks, producing more readable and well-formed text. These improvements reduce the need for manual corrections, allowing for more efficient document processing and analysis.
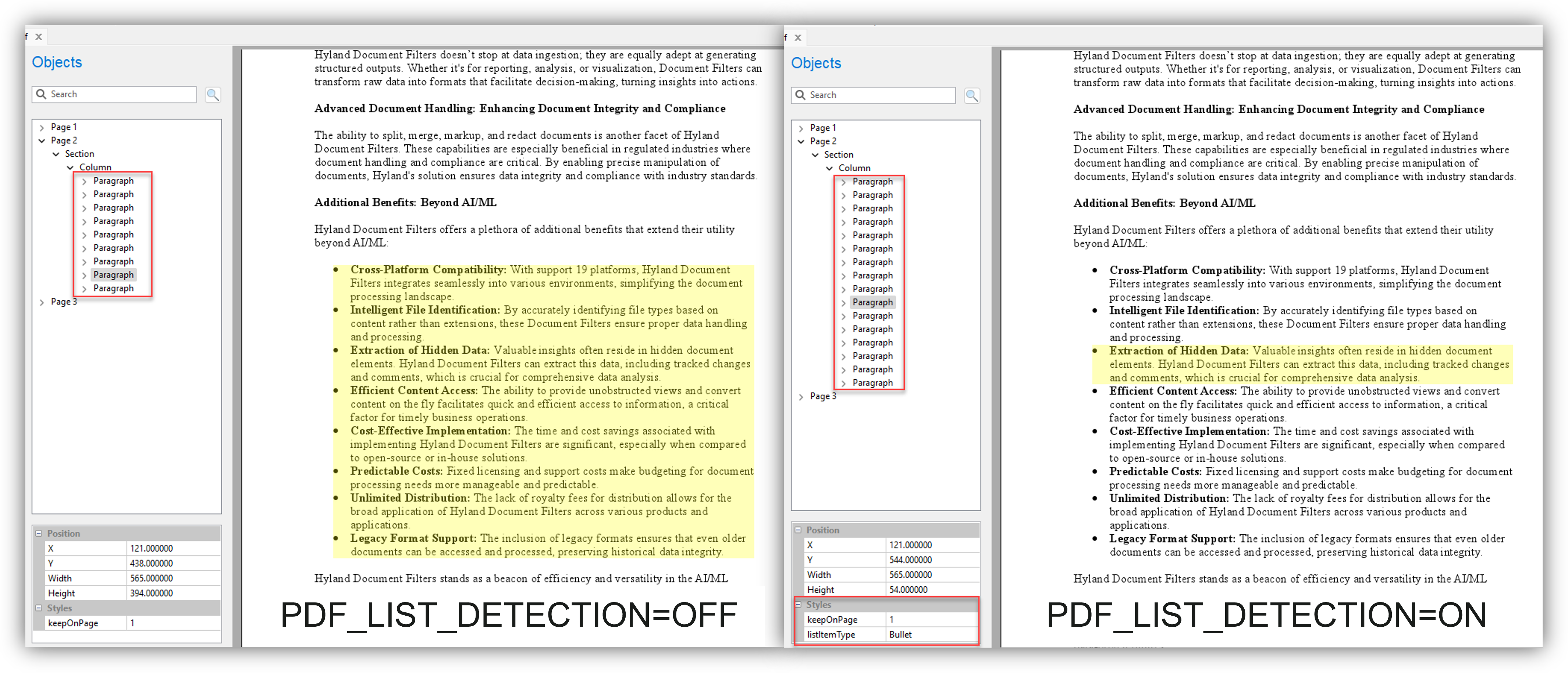
A comparison of when PDF_LIST_DETECTION is enabled and disabled. When enabled, we're able to identify each list item idividually, but when disabled, the list is flattened and identified together.
Release Links
- Document Filters 25.1 Release Notes
- Document Filters 25.1 Software Bill of Materials
- Enhancement Requests