This sample illustrates how to utilize the Hyland Document Filters SDK to convert a PDF document into HiDef Markdown format with enabled table detection. It provides a straightforward workflow for initializing the Document Filters API, opening the PDF document, and rendering its content into a well-structured Markdown output.
What You Will Learn:
API Initialization: Understand how to initialize the Hyland Document Filters API with a valid license code to enable document processing.
Document Opening: Learn how to open a PDF document for conversion to HiDef Markdown using the OpenExtractor method, ensuring the use of the correct open mode (e.g., Paginated) and enabling table detection with specific options.
Output Canvas Creation: Discover how to create an output canvas using the MakeOutputCanvas method, specifying the desired output file name and canvas type (e.g., MARKDOWN) to generate the Markdown structure.
Content Rendering: Learn how to render the document's pages into the output canvas, efficiently transforming the document's content, including detected tables, into Markdown format.
Resource Management: Gain insights into effective resource management in .NET by utilizing using statements to ensure that document and canvas objects are properly disposed of after use.
By following this sample, you will become familiar with the basics of setting up the Document Filters API, converting PDF documents to HiDef Markdown with table detection, and efficiently rendering document content for web applications.
#include<DocumentFiltersObjects.h>intmain(){try{// Create and initialize the API objectHyland::DocFilters::Apiapi;api.Initialize("License Code",".");std::wstringdocumentOptions=L"PDF_TABLE_DETECTION=ON;";std::wstringcanvasOptions=L"MARKDOWN_SIMPLE_TABLE_STYLE=GRID;";canvasOptions+=L"MARKDOWN_COMPLEX_TABLE_STYLE=HTML;";canvasOptions+=L"MARKDOWN_INCLUDE_FOOTERS=OFF;";canvasOptions+=L"MARKDOWN_INCLUDE_HEADERS=OFF;";canvasOptions+=L"MARKDOWN_INCLUDE_FIELDS=OFF;";// Open the input fileHyland::DocFilters::Extractordoc=api.OpenExtractor("filename.doc",Hyland::DocFilters::OpenMode::Paginated,0,documentOptions);// Create the output canvas Hyland::DocFilters::Canvascanvas=api.MakeOutputCanvas("output.md",Hyland::DocFilters::CanvasType::MARKDOWN,canvasOptions);// Render all pages to the outputcanvas.RenderPages(doc);}catch(conststd::exception&e){std::cerr<<"Error: "<<e.what()<<std::endl;return1;// Indicate an error}return0;// Successful execution}
#include<DocumentFilters.h>#include<stdio.h>#include<string.h>// License code and input file nameconstchar*license_code="";constchar*input_file="filename.doc";constchar*output_file="output.md";// Function prototypes for UCS2 and UTF8 conversionIGR_UCS2*UCS2(constchar*src,IGR_UCS2**dest);intmain(){// Initialization of status and control blocksInstance_Status_Blockisb={0};Error_Control_Blockecb={0};IGR_SHORTinstance=0;IGR_LONGcaps=0,type=0,docHandle=0,res=0,pageCount=0;IGR_HCANVAScanvasHandle=0;IGR_HPAGEpageHandle=0;IGR_UCS2*tempBuffer=NULL,*tempBuffer2=NULL,*tempBuffer3=NULL;;// Set license codestrncpy(isb.Licensee_ID1,license_code,sizeof(isb.Licensee_ID1)-1);// Initialize instanceInit_Instance(0,".",&isb,&instance,&ecb);constchar*document_options="PDF_TABLE_DETECTION=ON;";"MARKDOWN_COMPLEX_TABLE_STYLE=HTML;""MARKDOWN_INCLUDE_FOOTERS=OFF;""MARKDOWN_INCLUDE_HEADERS=OFF;""MARKDOWN_INCLUDE_FIELDS=OFF;";constchar*canvas_options="MARKDOWN_SIMPLE_TABLE_STYLE=GRID;";"MARKDOWN_COMPLEX_TABLE_STYLE=HTML;""MARKDOWN_INCLUDE_FOOTERS=OFF;""MARKDOWN_INCLUDE_HEADERS=OFF;""MARKDOWN_INCLUDE_FIELDS=OFF;";// Open the document fileres=IGR_Open_File_Ex(UCS2(input_file,&tempBuffer),IGR_FORMAT_IMAGE,UCS2(input_file,&tempBuffer2),&caps,&type,&docHandle,&ecb);if(res!=IGR_OK)gotoerror;// Create the output canvasres=IGR_Make_Output_Canvas(IGR_DEVICE_MARKDOWN,UCS2(output_file,&tempBuffer),UCS2(canvas_options,&tempBuffer3),&canvasHandle,&ecb);if(res!=IGR_OK)gotoerror;// Count the number of printable pagesres=IGR_Get_Page_Count(docHandle,&pageCount,&ecb);if(res!=IGR_OK)gotoerror;// Render the pages to the canvasfor(IGR_LONGi=0;i<pageCount;i++){if(IGR_Open_Page(docHandle,i,&pageHandle,&ecb)!=IGR_OK)gotoerror;IGR_Render_Page(pageHandle,canvasHandle,&ecb);IGR_Close_Page(pageHandle,&ecb);}gotocleanup;error:// Print error messageif(ecb.Msg[0]!=0)fprintf(stderr,"Error: %s\n",ecb.Msg);elsefprintf(stderr,"Error: %d\n",res);cleanup:// Free allocated resourcesif(tempBuffer)free(tempBuffer);if(tempBuffer2)free(tempBuffer2);if(tempBuffer3)free(tempBuffer3);if(canvasHandle)IGR_Close_Canvas(canvasHandle,&ecb);if(docHandle)IGR_Close_File(docHandle,&ecb);return0;}// Convert a UTF8 string to UCS2IGR_UCS2*UCS2(constchar*src,IGR_UCS2**dest){size_tlen=strlen(src);size_tdestSize=len*2+2;if(!*dest)free(*dest);*dest=malloc(destSize);if(!*dest)returnNULL;// Perform the conversionUTF8_to_Widechar_Ex(src,len,*dest,destSize);return*dest;}
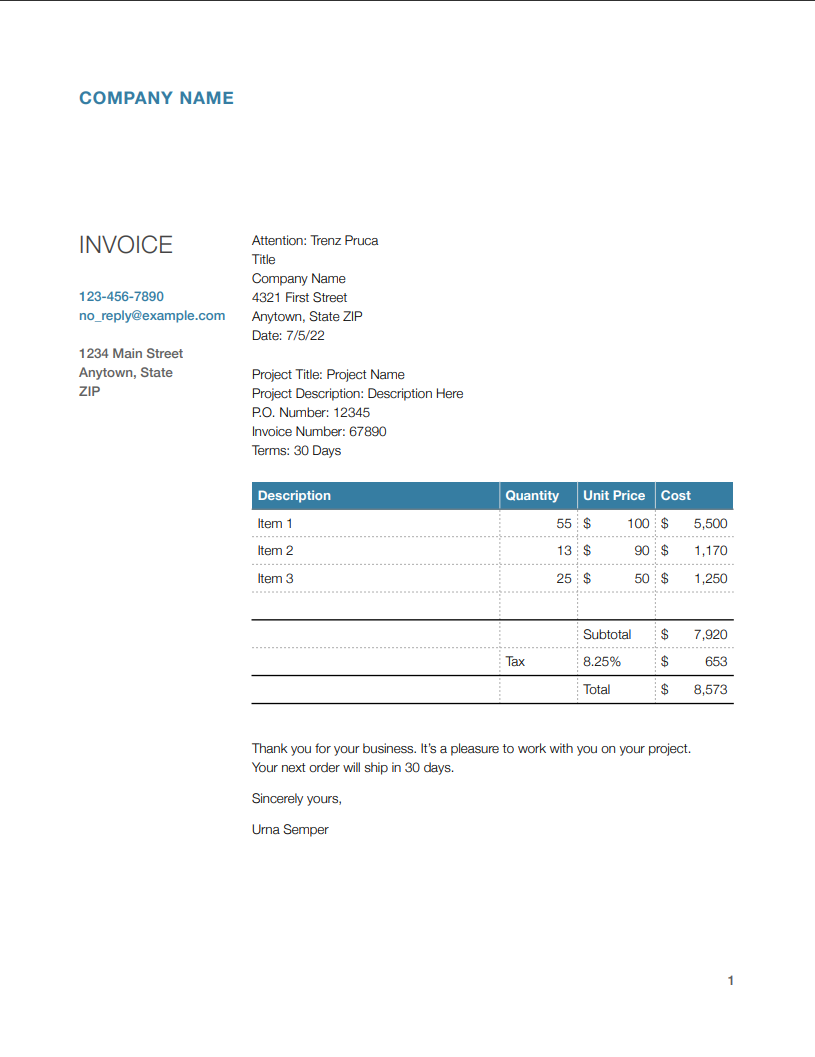
With PDF_TABLE_DETECTION enabled, the content is accurately represented in table format:
| **Description** | **Quantity** | **Unit Price** | **Cost** |
| --------------- | ------------ | -------------- | -------- |
| Item 1 | 55 | 100 | 5,500 |
| Item 2 | 13 | 90 | 1,170 |
| Item 3 | 25 | 50 | 1,250 |
| | | | |
| - | --- | -------- | ------ |
| | | Subtotal | 7,920 |
| | Tax | 8.25% | 653 |
| | | Total | 8,573 |
Thank you for your business. It’s a pleasure to work with you on your project.
Your next order will ship in 30 days.
When PDF_TABLE_DETECTION is not enabled, the line items in the table are treated as standard text, resulting in the following markdown output:
Item 1
55 100 5,500
Item 2
13 90 1,170
Item 3
25 50 1,250
Subtotal 7,920
Tax 8.25% 653
Total 8,573
Thank you for your business. It’s a pleasure to work with you on your project.
Your next order will ship in 30 days.
Note
Table detection is not an exact science; it involves interpreting the original intent from the available information in the file. As a result, it may occasionally misidentify content as a table or fail to detect existing tables.